
プロセスマイニング&タスクマイニングを実現するデータ基盤構築の下準備アプローチ

前回はデータドリブンマネジメントを実現するデータ基盤のあり方を考察するとともに、データ利活用を阻害する「組織・人」「データ」「ビジネス」「技術・基盤」の4領域についてその課題を紹介しました。
今回はこの4つの課題のうち、データ基盤構築に必要な「データの扱い」に焦点を当て、さらに深掘りをしていきましょう。
分析モデルの評価に有効なプロセスマイニング&タスクマイニングとは
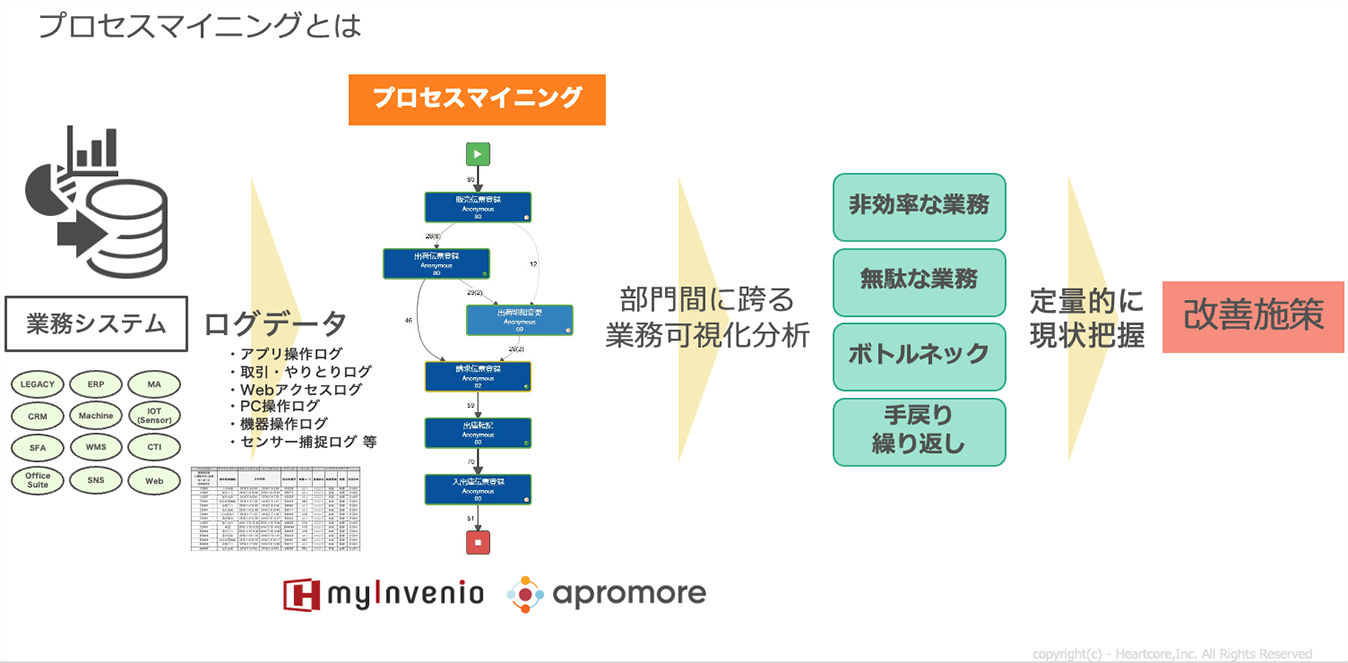
データドリブンマネジメントに必要な仕組みとして、「プロセスマイニング」と「タスクマイニング」があります。
プロセスマイニングとは1990年代後半にオランダで着想された概念で、「ERPのログを分析すれば業務プロセスのフローチャートを描けるのでは?」という考えから生まれました。
ERPをはじめとする各種業務システムには、操作ログが記録されています。そのイベントログを抽出し、分析します。つまり、個々の従業員が担うさまざまな業務のログを取得・分析し、一連の業務プロセスを可視化することで、業務全体の現状を把握して業務改善に活用しようという取組みです。
2018年には米国Gartnerが「Market Guide for Process Mining」というレポートを公開し、その考え方がヨーロッパを中心に急速に普及し始めました。Gartnerは2023年におけるプロセスマイニング市場が、1500億円規模になると予測しています。
プロセスマイニングの適用範囲は、業務プロセスに限定されるものではありません。たとえばWebサイトのアクセスログは、サイト訪問者のページの閲覧状況――言い換えるとサイト内回遊行動の記録――です。Webサイトのアクセスログをプロセスマイニングで分析すれば、 Webサイトにおける顧客の行動プロセスが可視化できます。このような顧客行動に対してプロセスマイニングを適用するアプローチは、「カスタマージャーニーマイニング」と呼ばれています。
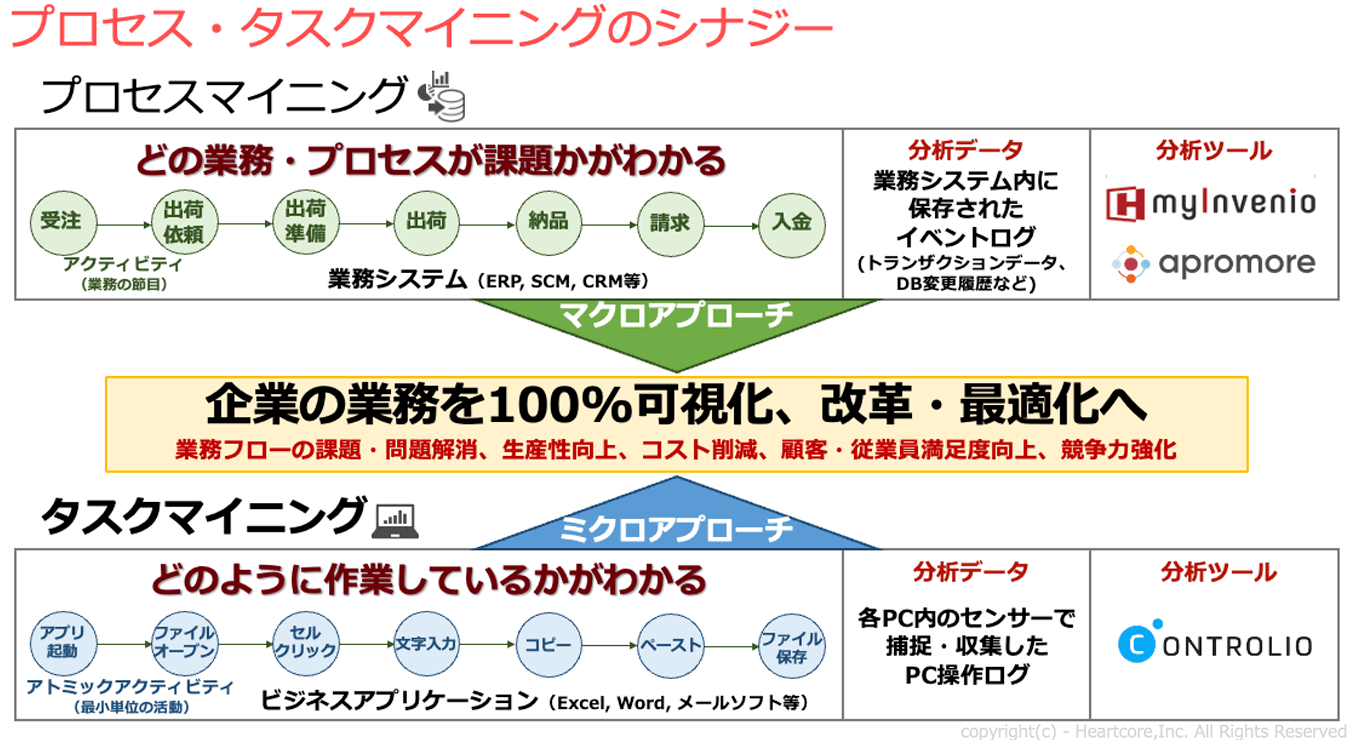
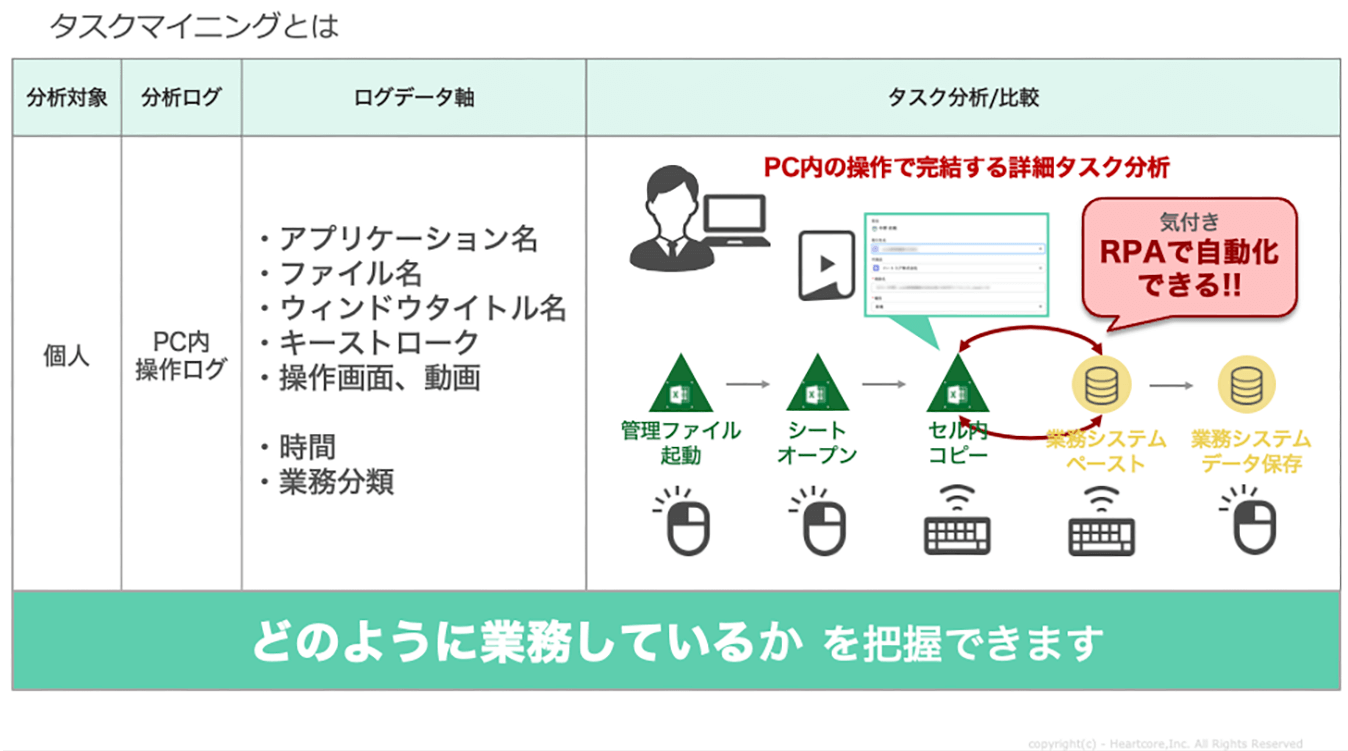
一方、タスクマイニングとは、さまざまな業務に従事する個々の従業員のPC操作ログデータを分析し、非効率な業務や、ボトルネック、繰り返し業務など、タスクレベルでの課題や問題点を可視化・分析する手法を指します。

PC操作には「アプリ起動」「画面立ち上げ」「ファイルオープン」「コピー&ペースト」などの詳細な操作があります。タスクマイニングによる業務改善は、業務プロセスの可視化を通じてプロセス全体を俯瞰することから始まります。
プロセスマイニング・タスクマイニングは「データ所在の可視化」「業務プロセス・タスクの可視化」「データ利活用」の3つの評価をする場合の有効な手段でもあります。経営層にデータ基盤の価値を理解してもらうもっとも効果的な方法は、 プロセスマイニング&タスクマイニング分析データを用いて説明することでしょう。
データ基盤構築に必要な観点とは
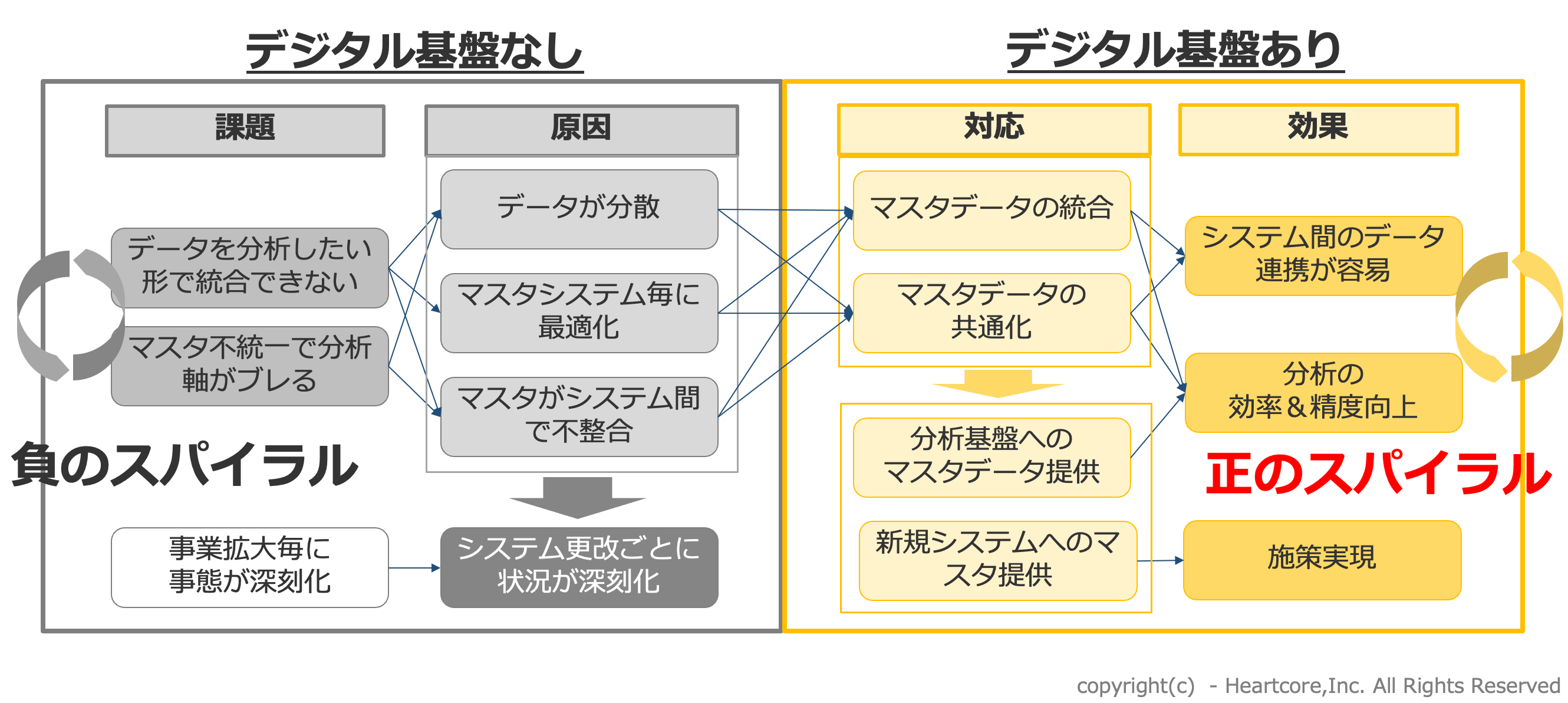
DXを推進するデータ基盤の構築には、現状のデータを見直し、「データがつながらない」「データ精度が低い」「必要データがすぐ入手できない」といった課題を解決して、データ活用の「正のスパイラル」を起こさなければなりません。 そのためには以下の視点を網羅し、データを一元的に管理できる基盤が不可欠です。
- 既存ERP(基幹システム)やDWH(データウェアハウス)に格納されているデータに対し、アドホックにアクセスできる
- データ種類と論理構造、およびデータの意味的な連関が可視化できる
- データにアクセスし、集計やマージなど任意の数値データが取得できる
データを一元的に管理する基盤の構築で最初に実施するのはデータを入手することです。前回も解説したとおり、これにはさまざまな課題を克服する必要があります。また、入手したデータに定義書がない場合には、データ加工や統合整備に時間がかかります。
この場合には分析のモデル構築段階で、どのような視点でデータを利活用するのか決定する取組みが必要になります。また、経営課題に対し、何のデータが必要なのかを明確化する必要もあります。
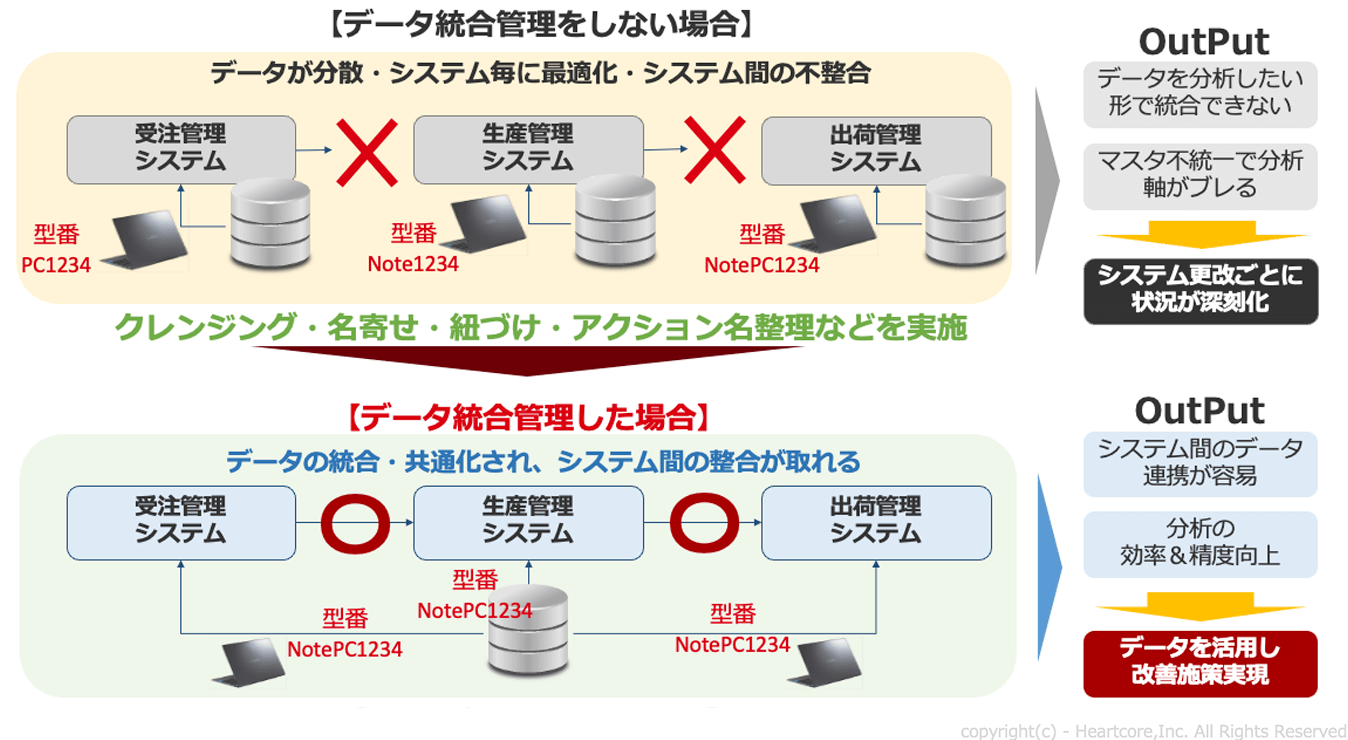
さらに、各システムのデータ定義が統一されていない場合は、ETL(Extract:抽出 Transform:変換 Load:書き出し)ツールを利用し、クレンジング・名寄せ・紐づけ・アクション名の整理を実施しなければなりません。 これによりシステム間のデータ連携が容易になり、分析効率やその精度が向上することで、データを活用した改善施策が実現できるようになります。
プロセスマイニング&タスクマイニング分析用ログの特徴
それでは、プロセスマイニングとタスクマイニングに必要な分析用データ(ログ)の特徴を見ていきましょう。
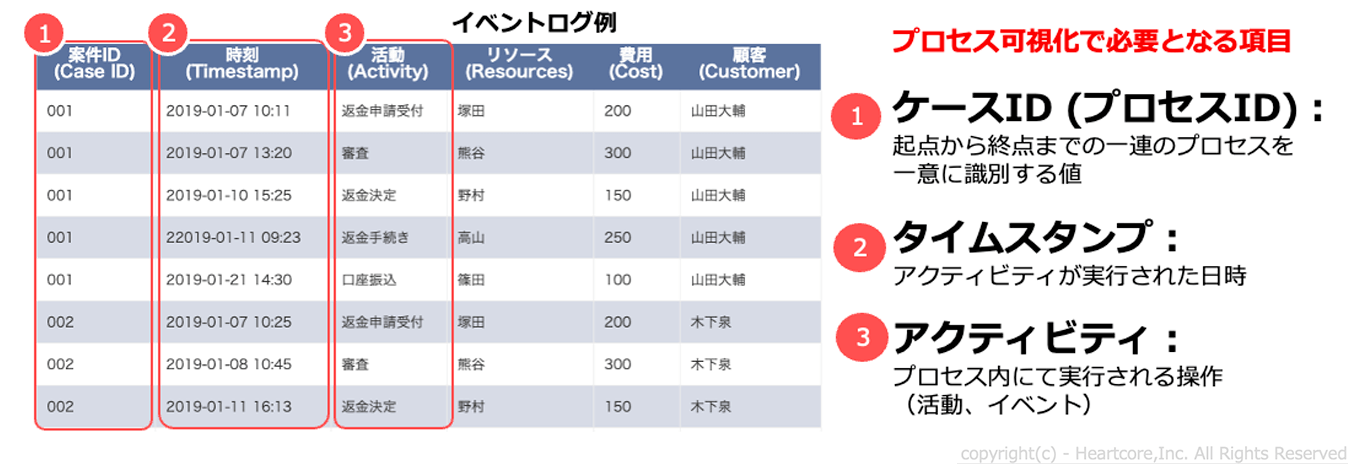
イベントログはシステムやアプリケーションなどの操作に対応し、操作内容(活動)がタイムスタンプとともに記録されたデータです。具体的には、基幹システムなどのデータベース(各テーブル)からデータ取得を行い、イベントログ形式に加工(クリーニング)したものを指します。
プロセスマイニング用イベントログは、下図のような「案件(CASE)ID」「アクティビティ(業務アクション名)」「タイムスタンプ」の3つのデータが中心です。この3つのデータさえ整理できれば、業務プロセスは可視化できます。また「リソース(従業員名)」などの属性データは、分析軸に応じて業務プロセス上の原因データとしてクロス分析が可能です。
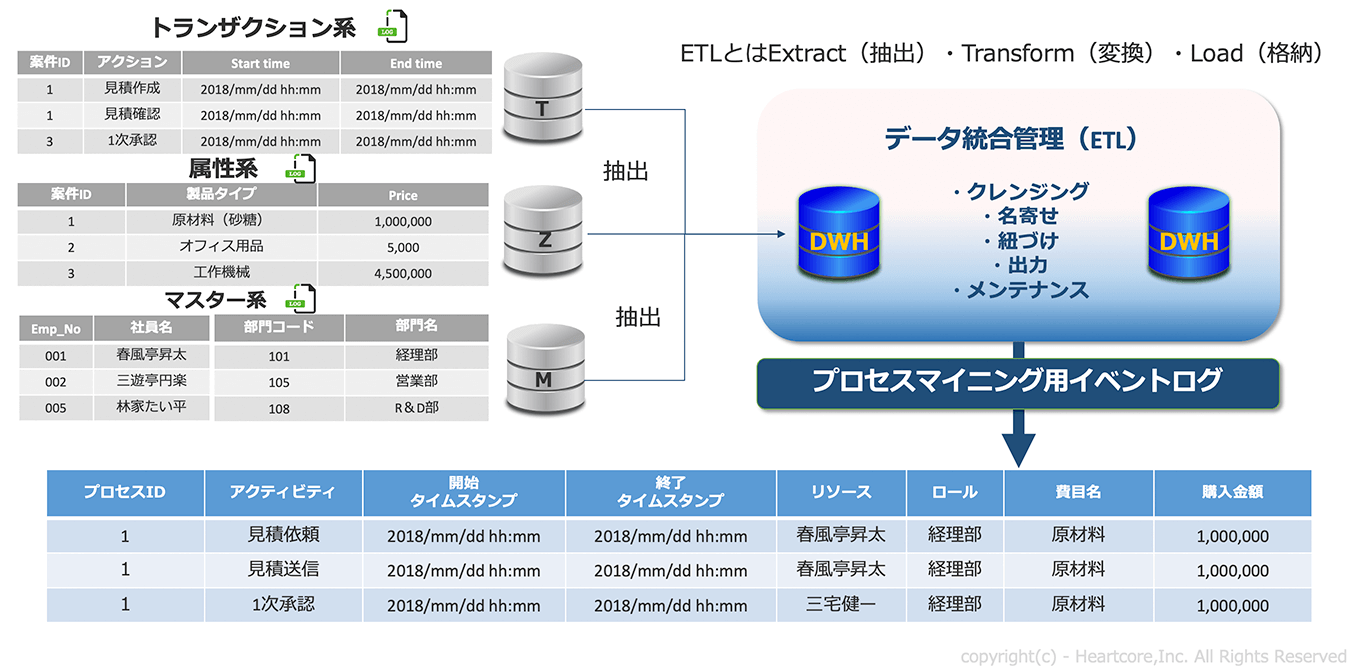
プロセスマイニング分析に必要となるイベントログは、「トランザクションデータ」「マスターデータ」「属性データ」の3種類の分析対象データを統合して分析します。 ただし、この段階でデータの「クレンジング・名寄せ・紐づけ」などのデータ統合が必要です。なお、このときにデータマネジメントとして、各データ定義の整理やER図やメタデータの整理・運用なども可能です。
一方、個人の業務タスクの可視化するタスクマイニング分析用ログは、PC操作ログを蓄積し、そのログを用いた業務分析への活用に特化したツールを活用します。 具体的な収集アプローチは「サーバ」と「クライアントコンピュータ(PC)」間を疎通し、「ユーザ」がPC上で操作(クリック、キー操作)した履歴データをリアルタイムに収集します。
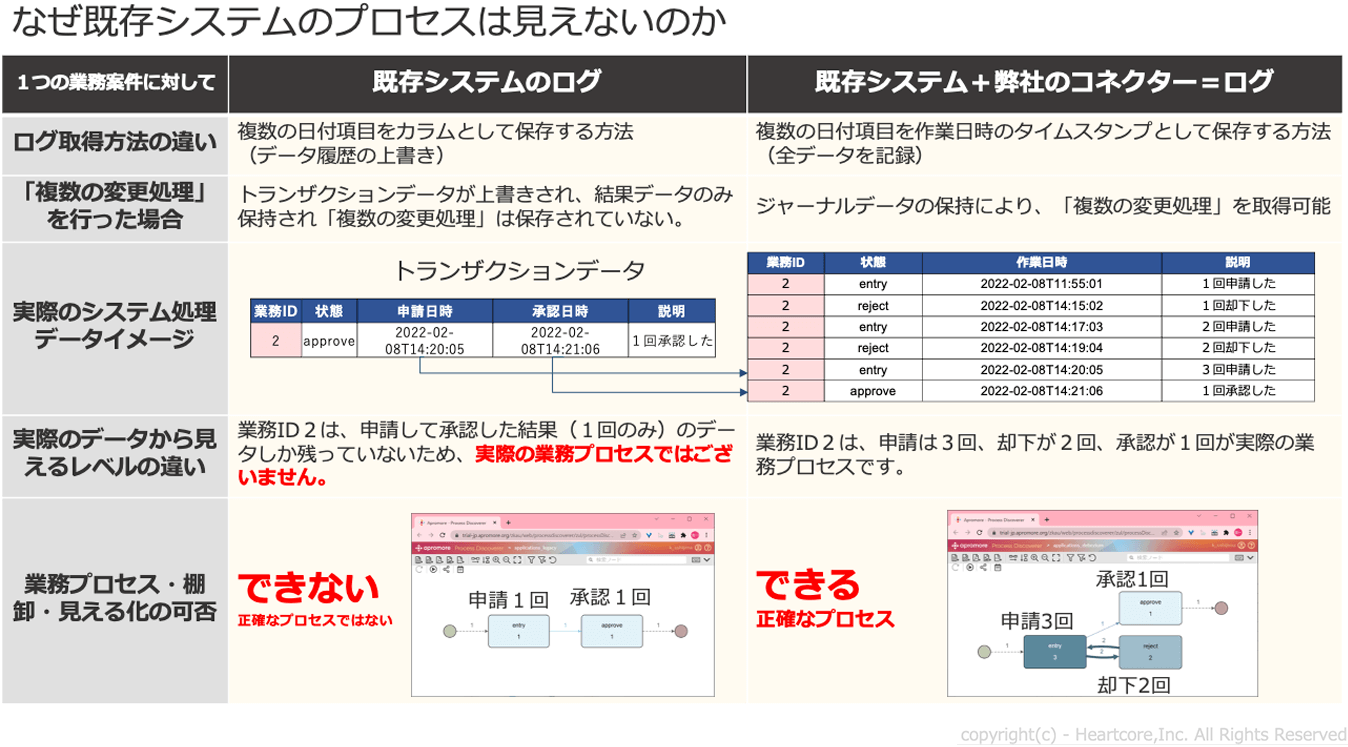
実は、データドリブンを実現するデータ基盤には「履歴データをリアルタイムに収集できる」ことが求められているのです。 もちろん、業務プロセス全体を可視化して個人の業務タスクを把握できることは大前提ですが、既存システムに格納されている“現状のログ”だけでは業務プロセスの最適化はできません。
たとえば、ログ取得の方法を考えてみましょう。複数の日付項目をカラムとして保存する方法では、データ履歴は上書きされてしまいます。これに対して複数の日付項目を作業日時のタイムスタンプとして保存する方法であれば、全データが記録されます。
また、複数の変更処理を行った場合にトランザクションデータが上書きされてしまえば、結果データのみが記録され、変更処理の履歴は保存されません。 これに対してシステムの稼働中に変更された箇所や変更内容などを時系列に記録した「ジャーナルデータ」を保持するアプローチであれば、複数の変更処理データを取得できるのです。
業務プロセスの可視化を意識した業務アプリ設計など、「国内のIT戦略に欠けていた時代」から脱却し、業務プロセス全体を案件IDで連携してデータドリブンな意思決定ができる環境基盤の構築は、これからの企業成長戦略に重要です。
そうした観点からも、プロセスマイニング&タスクマイニングの有用性を理解することは、経営層にとって必須事項なのです。次回はプロセスマイニング&タスクマイニングの有効性についてさらに深掘りしていきます。

